
Get a behind-the-scenes look at the search giant: Google was required to disclose internal documents shedding light on the search results ranking process as part of its antitrust lawsuit.
Revealing Google’s Ranking Methods
Documents recently released by the U.S. Department of Justice offer a behind-the-scenes look at Google, including how the search giant ranks results. These 7 internal documents, which include PowerPoint presentations and emails, shed light on the criteria and processes that influence the visibility of web pages in Google search results.
Please note: some of these documents are several years old, so the information contained should be taken with a grain of salt, as they may have been modified in the meantime.
User Interactions
The first document is a PowerPoint presentation written largely by Eric Lehman. It dates back to 2017. Not all pages are accessible.

According to the “The 3 pillars of ranking” slide, Google highlights 3 elements:
- The body: what the document says about itself;
- Anchors: what the web says about the document;
- Interactions: What users say about the document.
Google clarifies that clicks can be used as a substitute for user interactions. Taken together, interactions include clicks, paying attention to a result, clicking on a carousel, hovering over, scrolling, and entering a new query.
Link: Google presentation: Life of a Click (user-interaction) (May 15, 2017) (PDF)
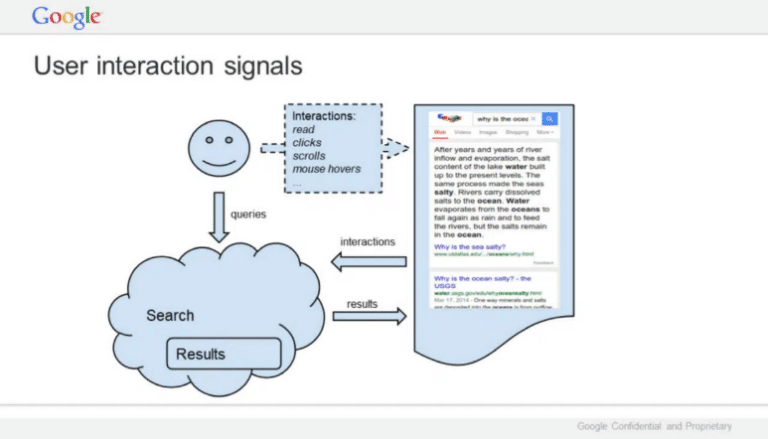
Rankings
The second document revealed is a presentation prepared by Eric Lehman in 2016 about rankings. So it’s 7 years old, which means that Google has gone through multiple evolutions since then. It’s no less interesting, but don’t take it for granted today.

Among other things, Lehman states that Google pretends to understand documents, but it doesn’t: “Our ability to understand documents directly is minimal. We observe how people react to documents and remember their responses.”
Beyond a few basic elements, we barely look at the documents. We look at the Internet users. If a document gets a positive reaction, we think it’s good. If the reaction is negative, it’s probably bad.
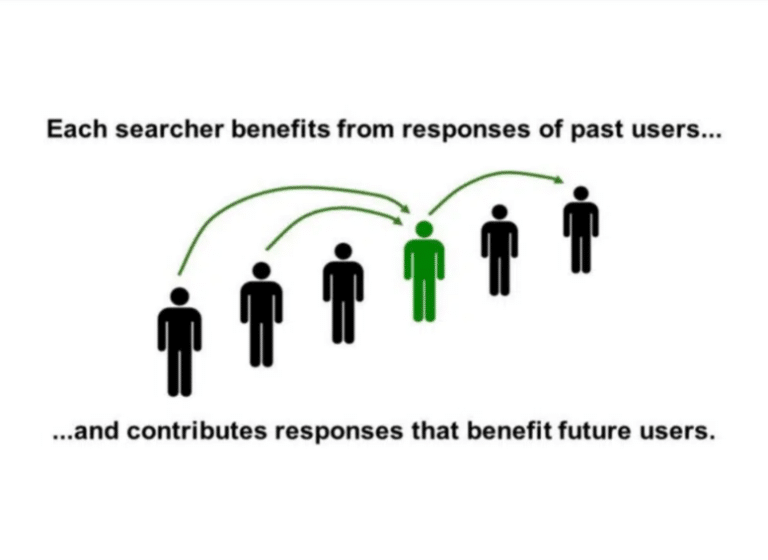
This slide shows that each researcher benefits from the answers of previous researchers, to provide better answers. The search engine learns from previous interactions so that the experience continuously improves.
While user interactions are certainly still important for ranking results, it goes without saying that Google’s understanding of content has improved significantly since 2016.
Link: Google presentation: Q4 Search All Hands (Dec. 8, 2016) (PDF)
Quality of Research
The author of this presentation is unclear, but it is from November 2018. Again, some of the information is surely still correct, but other criteria have had to be added since then.

Google addresses 18 aspects of search quality: relevance, page quality, popularity, freshness, localization, language, personalization, web ecosystem, mobile-friendly, spam, authority, privacy, etc.
This presentation also indicates that clicks are difficult to interpret, and therefore not a good ranking signal: a backpedal compared to the 2017 presentation? That’s not to say that clicks aren’t used in the ranking system today, but maybe their importance is worth weighing?
Link: Google presentation: Ranking for Research (November 16, 2018) (PDF)
Google is Magic
Let’s go back to 2017 with the presentation “Google is magic,” which contains several interesting slides.
In particular, how Google Search doesn’t work:

And how it works:
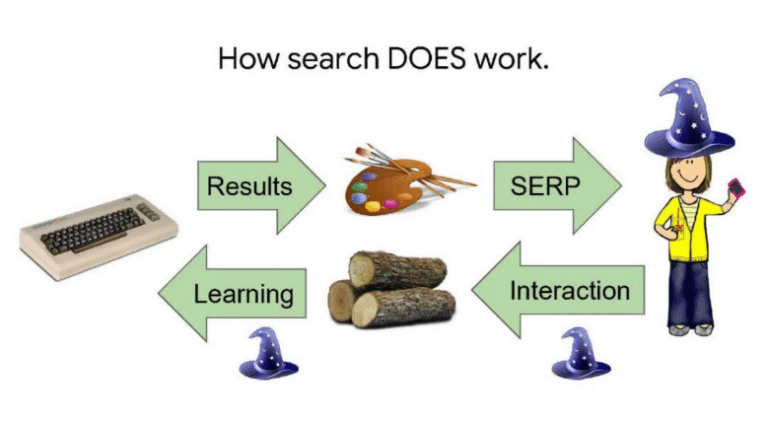
The first slide was therefore not wrong, but incomplete because it did not take into account the second flow of information, from the user to the search engine. Actions are recorded and this allows templates to be created.
The source of Google’s magic lies in this two-way dialogue with users. With each request, we pass on knowledge and get a little in return. Then we give a little bit more and get a little bit more back in return. These elements add up. After a few hundred billion returns, we’re starting to look pretty smart! It’s not the only way to learn, but it’s the most effective.”
Link: Google presentation: Google is magical. (October 30, 2017) (PDF)
Logs & Ranking
This presentation from 2020 (already more recent!) discusses the essential role of logs in ranking and search.
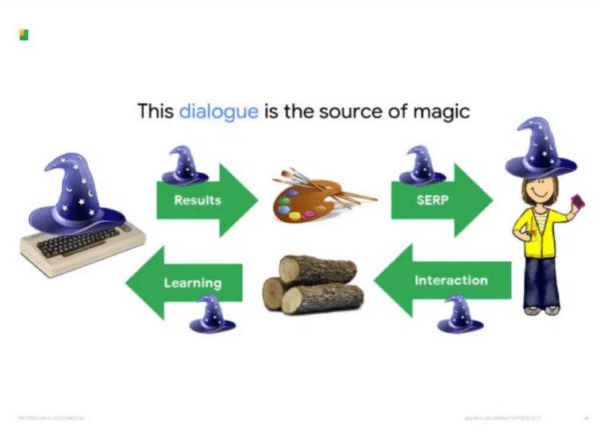
We can be reassured, because the way Google works seems not to have changed since the 2017 presentation, the slide being almost identical.
“Research is a bit like a ‘potluck,’ where each person brings a dish to share. This is a very wide variety of dishes that everyone can enjoy. But it only works because everyone contributes a little.
In the same way, research is based on an enormous body of knowledge. But it’s not something we create. On the contrary, everyone who comes to do research brings a little knowledge to the system that everyone can benefit from.”

Google then talks about extracting value judgments from user behaviors.
“Logs don’t contain explicit value judgments: it was a good search result, or this one was bad. So we need to think about how to translate the behaviors of registered users into value judgments. Translation is really tricky, a problem that people have been working on quite regularly for over 15 years. People work on it because value judgments are the foundation of Google search. If we can extract a fraction of a little more meaning from one session, we’ll get about a billion times more the next day. The basic game is that you start with a small amount of “ground truth” data that indicates that such and such a thing on the search page is good, this is bad, this is better than that. Then you look at all the behaviors of associated users and say, “Ah, that’s what a user does with a good thing! That’s what a user does with a bad thing! That’s how a user shows their preference!” Of course, people are different. So we only get statistical correlations, nothing really reliable.”

The author of the document then confirms that logs are fundamental for search engine rankings:
“As I mentioned, not just one system, but a lot of rankings are built on logs. These are not just traditional systems, like the one I showed you earlier, but also more advanced machine learning systems, many of which have been announced externally: RankBrain, RankEmbed, and DeepRank. (…) Generally speaking, I think a huge part of Google’s business is related to the use of logs in the rankings.”
Mobile/Desktop Ranking
An email about the differences between desktop and mobile search rankings has also been made public, but it’s from 2014. In other words, mobile traffic was just beginning to overtake desktop traffic… Whereas today, all sites are indexed on their mobile version!
Link: Google presentation: Logging & Ranking (May 8, 2020) (PDF)
First Experiences with BERT
Finally, a very small document containing a bulleted list for a presentation for Sundar Pichai, dating from September 2019, has been added to the parts list.
2 points about BERT are nevertheless interesting:
“Early experiments with BERT applied to several other areas of search, including web ranking, suggest very significant improvements in understanding queries, documents, and intents.”
“While BERT is revolutionary, this is just the beginning of a leap forward in natural language understanding technologies.”
Link: Google document: Bullet points for presentation to Sundar (Sept. 17, 2019) (PDF)
All these documents, although useful to know to improve our understanding of how Google works, should be taken with caution. The confidential parts have been removed. What is public must therefore be of lesser importance. Maybe because this information was already more or less known? Or because they are no longer relevant? Some information, such as user interactions or logs, is nevertheless interesting and should certainly be taken into consideration in your SEO strategy.”
Did you like this article? Do not hesitate to share it on social networks and subscribe to Tech To Geek on Google News or our facebook page to not miss any articles!"Because of the Google update, I, like many other blogs, lost a lot of traffic."
Join the Newsletter
Please, subscribe to get our latest content by email.